統計的ダイバージェンスに基づく頑健なモデル選択規準

倉田 澄人
学位:博士(理学) (大阪大学)
専門分野: 数理統計学、モデル選択、ロバストネス
例えば突出した能力、例えば災害級の現象、例えば観測機器の故障、例えば人的なミス…等々、現実のデータには様々な由来を持った、他の観測値から見て大きく外れた値を取るデータが付き物です。これを「外れ値」と呼びます。この外れ値ですが、何を以て外れ値とするか、どこまでが外れ値でなくどこからが外れ値であるかという明確な定義、線引きは与え難いものです。また、災害やミスを完全に零にするということが非常に難しいため、外れ値の発生を防ぐことは事実上不可能と言わざるを得ません。その為、外れ値が混ざっていてもその影響を小さく抑えられる「頑健(ロバスト)」な分析手法が、分析において重要な意味を持つと考えられます。私は、モデル選択問題を中心に、頑健な手法について研究を行っています。モデル選択規準は、自然現象や人間の行動を表現する数理モデルの候補の中から最も好ましいモデルを択ぶ尺度です。私はこれまで特に、確率分布間の遠さを測る「統計的ダイバージェンス」を用いて、現象や行動の根底に在ると考えられる「真の分布」とモデルとの近さを測るという観点から導出されるモデル選択規準を検討してきました。モデル選択問題を考えるにあたっても、頑健性は重要な性質と言えるでしょう。しかし、従来広く用いられている、Kullback-Leiblerダイバージェンスに基づいたモデル選択規準は、データに外れ値が混ざっていると選択精度を落としてしまう傾向にあることが指摘されています。そこで本研究では、統計的推測において頑健性に優れることが知られている、「BHHJダイバージェンス」と呼ばれるダイバージェンスに基づいて、従来のAICやBICを拡張したモデル選択規準を導出し、検討してきました。
外れ値は頻繁に、パラメータ推定やモデル選択へ悪影響を及ぼします。モデル選択における頑健性を議論する為には、モデル選択規準の値の、外れ値によって生じる変動を評価する必要があると考えられます。本分野ではしばしば、データを発生させている分布に外れ値が含まれている場合といない場合との差を評価することで、外れ値の混合に対する敏感さを評価します。観測値の大部分は「真の分布」から発生していると想定し、そして外れ値は「真の分布」とは別の分布から出現しているものだと解釈します(図1)。私はこれまで、多くのダイバージェンスに基づいたモデル選択規準の頑健性を比較検討してきました。結果として、BHHJダイバージェンスを筆頭に、幾つかのダイバージェンスに基づいた規準の頑健性が分かってきました(図2)。あらゆる現象に対してモデルが作成出来る以上、良きモデル選択規準を検討することは、あらゆる分野に対して意義を持ちます。頑健性をはじめ、選択に資する様々な性質を詳しく調べることで、文理を問わず幅広い分野を支えられる研究を目指しています。
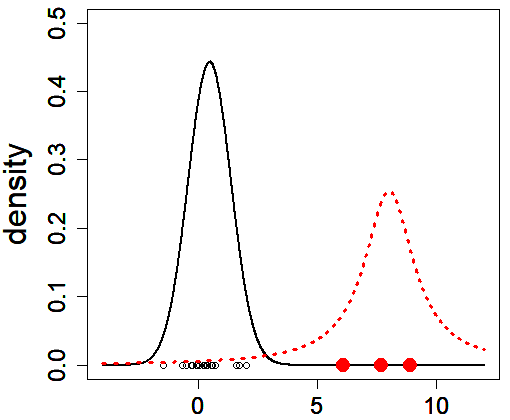
(図1) 一つは黒い線で画かれた「真の分布」、もう一つは赤い線の外れ値を発生させる分布、これらの異なる確率分布を考え、観測値はこの二つの分布の混合から発生していると想定します。もし、黒の分布のみからデータが出てきているときと、混合分布から出てきているときで分析結果が大きく異なれば、その手法は外れ値に対して敏感(頑健ではない)と考えることが出来ます。
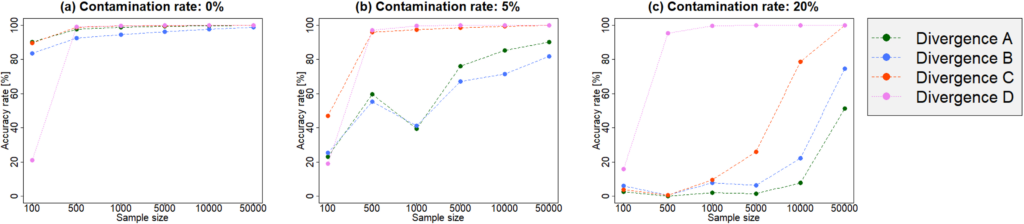
(図2) 一般化線形モデルの数値シミュレーションにおける、幾つかのダイバージェンス(Divergence A-D)に基づいたモデル選択規準のaccuracy rate (正しいモデルを選択した率)です。三つのグラフは異なる外れ値の混合率(0%、5%、20%)に対応しており、それぞれの横軸はサンプルサイズ(観測データの個数)を指します。Divergence AとBに基づく規準は外れ値があると精度が大きく下がっており、混合による悪影響を敏感に受けていることが分かります。一方でDivergence Dの規準は、全ての混合率に対してほぼ同じaccuracy rateになっており、強い頑健性が見て取れます。